Apach Axiom VS Java DOM 성능 비교
JAVA 의 xml parser 중 하나
구조
JDOM
- 전체 파일을 읽어와서 Tree 형식으로 구조화해서 메모리에 올려놓기 때문에 메모리 관리 면에서 불리
- 한번 파싱하면 계속 조회/수정이 가능한 장점이 있음
AXIOM
- Tree 구조가 아닌 StAX API 를 기반으로 직접 접근하는 방식으로 메모리 관리에서 유리
- 조회/수정이 필요할 때 마다 계속 파싱해야하는 단점이 있음
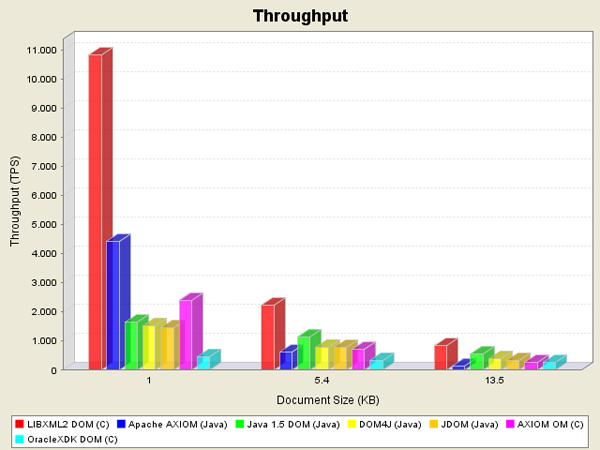
성능 비교 ( y축 : 처리량 / x축 : 문서 크기 )
테스트1 : 문서 전체를 파싱
문서 전체를 파싱하는건 Axiom 장점중 하나인 원하는 Element 만 파싱할 수 있다는 점을 발휘하지 못한다.
테스트2 : 각 용량별 XML 파일에서 67개의 Element 만 파싱
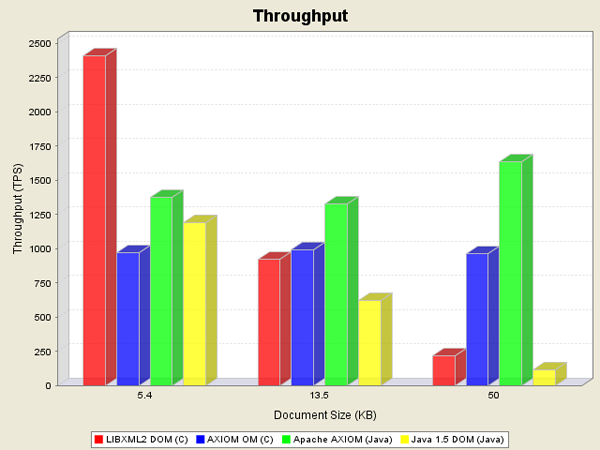
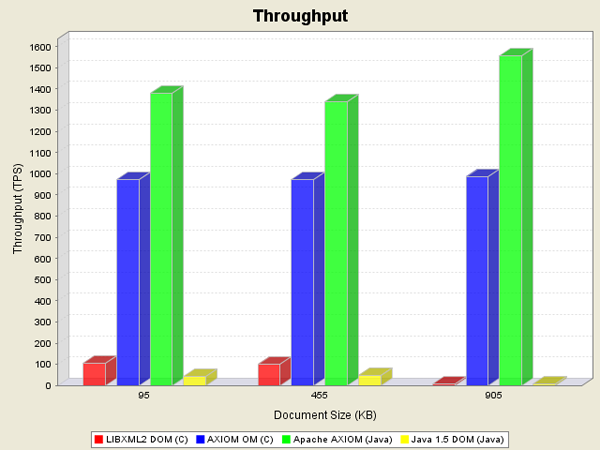
- XML 파일의 크기가 커질수록 JDOM 과 성능 격차가 많이 벌어진다.
- 다른 XML Parser API는 Element 전체를 가져와서 Tree 구조화 시킨 후 값을 반환하기 때문에 성능면에서 불리하다.
참조 문서 : https://www.xml.com/pub/a/2007/05/16/xml-parser-benchmarks-part-2.html
XML Parser Benchmarks: Part 2
XML Parser Benchmarks: Part 2 May 16, 2007 Matthias Farwick and Michael Hafner In part 1 of this series we showed you the results of our event-driven parser benchmarks. The outcome of these benchmarks showed that the LIBXML2 SAX-like parser in C is superio
www.xml.com
Axiom API 사용법
XML에 접근하기 위해선 먼저 Document 객체를 생성해야 한다.
//파일 Stream 취득 후 XML Reader 생성
XMLStreamReader parser = XMLInputFactory.newInstance().createXMLStreamReader( InputStream );
StAXOMBuilder builder = new StAXOMBuilder( parser );
//XML Document 객체 생성
OMElement nodeRoot = builder.getDocumentElement();OMElement nodeRoot = builder.getDocumentElement();
- XML의 Element 형태
- XML의 파일을 읽어와서 최상단 태그를 가져옴
OMElement node = nodeRoot.getFirstChildWithName( new QName( "abcd" ) );
- 반환타입 : OMElement
- QName : Element의 태그를 가르킴 ( 태그명 OR 속성명 ) <abcd abcd="attr"></abcd>
- nodeRoot 의 하위 Element 중에 <abcd></abcd> 반환
Iterator itr = nodeRoot.getChildElements();
- 반환타입 : Iterator
- nodeRoot 에 포함된 모든 Element 반환 ex) <nodeRoot> <Element1 /> <Element2 /> </nodeRoot>
OMElement node = (OMElement)itr.next();
- 반환타입 : OMElement
- itr.next() : Iterator에 들어있는 데이터 하나를 가져온 후 다음 데이터를 가르킴
- 가져온 데이터를 Element 로 형변환
String tag = node.getLocalName();
- 반환타입 : String
- <node></node>에서 태그 명 node를 String 형태로 반환
String value = node.getAttributeValue( QName qname ); return : String
- <node qname="value">text</node> 라는 태그가 있을 경우 "value"를 String 형태로 반환
String text = node.getText(); return : String
- <node qname="value">text</node> 라는 태그가 있을 경우 text를 String 형태로 반환
Iterator itr = node.getAllAttributes(); return : Iterator
- 반환타입 : Iterator
- <node att1="val1" attr2="val2"></node> 안에 모든 속성 attr 을 가져옴
OMAttribute attr = (OMAttriute)itr1.next();
- 반환타입 : OMAttribute
- Iterator에 들어있는 데이터 하나를 가져옴
- attr.getLocalName() : 속성명
- attr.getAttributeValue() : 속성값
'Back-End > Java & Spring' 카테고리의 다른 글
| [JAVA] Log4j (0) | 2022.08.02 |
|---|---|
| [JAVA] JNDI( Java Naming and Directory Interface ) (0) | 2022.08.02 |
| [JAVA] JVM 메모리 구조와 라이프 사이클 (0) | 2022.08.02 |
| [JAVA] Java Framework 종류 (0) | 2022.08.02 |
| [JAVA] Collection Framework 정의/성능 비교 (0) | 2022.08.02 |